在以前工作的项目中,没少和字符编码打交道。
在做手机短信相关的项目时,发送中文短信需要将GB2312的编码的字符按照UNICODE编码打包到PDU中,很多年前单片机上没有系统或者只有很简陋的系统,那时候我们采取的是查表映射的方法。
在做液晶屏相关的项目时,对于包含字库的控制芯片,要在液晶上显示文本等信息,我们的做法是自已生成一个按区位码汉字点阵库,然后程序读取点阵信息再在液晶屏上对应的位置按点阵信息点亮或者熄灭对应的点来达到显示汉字的目的。
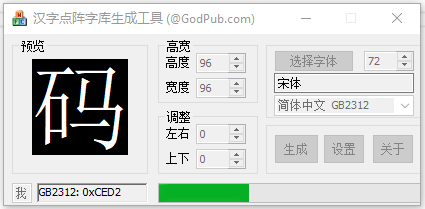
那么什么ASCII、GB2312、Unicode、UTF-8、机内码又都是些啥,都有些啥关系呢?反正每次项目用到的时候,我都搞得挺明白的,然后过段时间又忘得干干净净,比如我如何去我自己实现的汉字库中读取一个汉字的点阵出来呢?
每每这个时候,我就要陷入到深深的思索当中,然后把这些信息通通在脑子里过一遍,然后过段时间,再忘掉它😳。于是我决定简单的回忆和记录一下,下次再用到,我翻这篇文章就可以了,真聪明啊。
ASCII
ASCII即American Standard Code for Information Interchange(美国信息交换标准代码)。
ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。标准ASCII 码也叫基础ASCII码,使用7 位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0 到9、标点符号, 以及在美式英语中使用的特殊控制字符。
对于人家老美而言,有这套编码似乎就足够了,什么大小写字母、数字、标点全不在话下,但是到了中国和日本等国家,我们使用计算机就面临一个艰难的抉择,要么就是全用英文不再计算机上使用方块字,要么就是弄一套自己的编码。幸好,在计算机科技发展初期,国人没犯懒,否则可能我就没法在STEEMIT上用中文写文章了。
GB2312 / 区位码 / GBK
既然ASCII只能存储西文字符,那么如果要编码中文汉字啥的咋办?128个或者256字符显然不够,小学生现在都要掌握几千汉字呢。所以早在80年代,中国国家标准总局就发布了《信息交换用汉字编码字符集》,也就是GB 2312—1980。
这套编码用两个字节来表示对应的符号,将所有带编码字符(汉字6763个和非汉字图形字符682个)分成94个区每个区有94位,每个字符占一个位。你可以将区和位想象成一个94X94的表格,每个格内放一个字符,用区号和位号可以定位到字符,这就是区位码。
将区号和位号分别加0xA0,并放入两个字节,就是我们通常说的GB2312编码(也叫EUC-CN表示法,这样做的目的是为了便于兼容ASCII。
说到GB2312,又不得不提一下GBK编码,GBK即《汉字内码扩展规范》(GBK即“国标”、“扩展”汉语拼音的第一个字母,英文名称:Chinese Internal Code Specification)。
GBK 向下与 GB 2312 编码兼容,向上支持 ISO 10646.1国际标准,是前者向后者过渡过程中的一个承上启下的产物。ISO 10646 是国际标准化组织 ISO 公布的一个编码标准,即 Universal Multilpe-Octet Coded Character Set(简称UCS),大陆译为《通用多八位编码字符集》,台湾译为《广用多八位元编码字元集》,它与 Unicode 组织的 Unicode 编码完全兼容。
Unicode
无论是GB2312也好还是后来的扩展GBK也罢,显示汉字甚至日文平假名片假名等都毫无压力,但是如果藏文呢?蒙古文呢?还有其它一些国家乱七八糟的文字呢?总不能英语和汉语一统江湖吧?
当然了,对于别的国家会有类似GB2312的编码出现,所以我们计算机设置语言的时候要有一个非UNICODE编码识别成啥语言,否则它不清楚对于一段代码是识别成蒙古文好呢?还是泰国文字好呢?
这时候,Unicode出现了,你看这个名字就霸气,大统一编码。也就是说它的编码囊括事业上所有语言的所有的字符,这样因为两个不同的字符不会出现相同的编码,就不会打仗不会乱码了。
确切地说,Unicode是包含字符集、字符编码在内的全套标准,而UTF-8、UTF-16、UTF-32、UCS-2等则为编码方案。
通常我们程序中提到用到的Unicode编码都指的是UCS-2,也就是将字符编码到两个字节中,但是呢,它过时啦。
UCS-2 uses two bytes (16 bits) for each character but can only encode the first 65,536 code points, the so-called Basic Multilingual Plane (BMP). With 1,114,112 code points on 17 planes being possible, and with over 137,000 code points defined so far, many Unicode characters are beyond the reach of UCS-2. Therefore, UCS-2 is obsolete, though still widely used in software. UTF-16 extends UCS-2, by using the same 16-bit encoding as UCS-2 for the Basic Multilingual Plane, and a 4-byte encoding for the other planes. As long as it contains no code points in the reserved range U+0D800-U+0DFFF, a UCS-2 text is a valid UTF-16 text.
UTF-8是比较常用的编码方案了,尤其是在网络上传输数据时。
从Unicode到UTF-8的编码方式如下: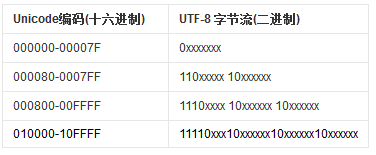
所以尽管它后边带个8,但是它的长度是不固定的,也就是说是变长编码。对于ASCII字符而言,按上述规则编码出来的UTF-8编码与ASCII完全相同,只占一个字节。在网络上传输数据时,这种编码方案会更加节省网络流量。
区位码
在GB2312条目下,我已经介绍了区位码。之所以在单独提出来,是想回到当初的问题:“我如何去我自己实现的汉字库中读取一个汉字的点阵出来呢?”
因为我的点阵库是按区位码放置,除了界面上的设置外,我们还可以点设置按钮进行一些设置: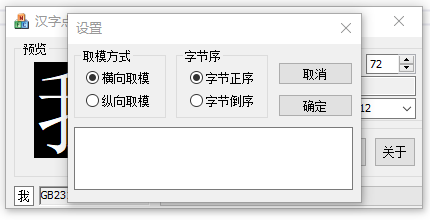
知道了这些,那么我们传入一个汉字,首先获得它的GB2312编码,然后根据区位码的规则计算出区位,在根据汉字点阵的长宽计算出每个汉字点阵的字节,根据区位、单个点阵字节数,计算出对应点阵在点阵库中的偏移量,取出对应字节即可。
至于横向纵向,倒序正序我是时常迷糊的,不过这个好办,显示的汉字颠倒了,我再改程序即可😀
文章为个人理解,错漏难免,仅供参考
参考资料
This page is synchronized from the post: 温故而知新:复习一下字符编码(ASCII、GB2312、Unicode、UTF-8、区位码)