在Memo使用AES加密的过程中,除了使用到shared_secret外,还涉及到两个数值:分别是nonce以及check。

(图源 :pixabay)
nonce & check
其中nonce是一个64位的随机数(8字节),在BM的一篇文章中曾有提及:
The purpose of the ‘nonce’ field is to generate a unique encryption key for every transfer between two accounts. I it should be a random number.
而check则是密钥的32位(4字节)摘要,保证字节串中内容没被破坏掉(其实我觉得并没有啥用,因为它只对加密密钥检查,并没有检查加密后的信息)
这两个数值的具体作用我们就简单说到这里,之所以提到这两个数值,是因为这两个数值要和加密后的文本一起用base58编码打包进memo。
因为打包用的是字符串串接,所以我自作聪明地写了类似如下代码:
str_nonce = '%016x' % noncestr_check = '%08x' % check
目的是把这两个转成字符串,然后串接到Memo包里。然而加密Memo是生成了,解密时却出现:
assert check == checksum, “Checksum failure”
AssertionError: Checksum failure
这充分说明我传入的数值不对嘛,可是问题出在哪里呢?我百思不得其解。
字节序 / Byte Order
其实稍微分析一下,这事就不难想明白。我不过是将数据打包进memo,然后再拆包出来,拆包的部分代码如下:
nonce = str(struct.unpack_from("<Q", unhexlify(raw[:16]))[0])raw = raw[16:]check = struct.unpack_from("<I", unhexlify(raw[:8]))[0]‘
注意到什么了没有?没错,就是字节序(Byte Order)的问题!什么叫做字节序呢?简单来讲就是:
大于一个字节类型的数据在内存中的存放或者传递时顺序。
而Python struct 中字节序的标识如下:
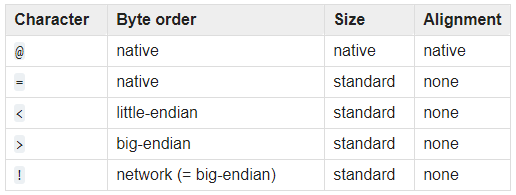
由此不难看出,我们解包时是按little-endian(<)解包nonce和check的,亦即:
低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
再对比一下如下代码:
a = 0x0123456789abcdefstr_1 = '%016x' % astr_2 = hexlify(struct.pack("<Q", a)).decode()str_3 = hexlify(struct.pack(">Q", a)).decode()print(str_1, str_2, str_3)
输出为:0123456789abcdef efcdab8967452301 0123456789abcdef
由此可见,直接用%016x生成的字符串是把原数据按Big endian放置的!
解决方法
知道了引起错误的原因是因为字节序问题,那么解决起来就好办多了,使用如下代码生成字符串即可:
str_nonce = hexlify(struct.pack("<Q", int(nonce))).decode()str_check = hexlify(struct.pack("<I", int(check))).decode()
你可能会问,既然是字节序问题,那么我们解包的程序也按着相同的字节序处理不也一样嘛?道理是这个道理,不过问题是无论打包还是解包都单单自己要用,你可能要给别人发送memo,也可能接收别人的memo,所以必须按着相同的规范和标准来哦。
相关链接
This page is synchronized from the post: ‘每天进步一点点:字节序的问题 (little-endian/big-endian)’