帮别人写一个小脚本,其中需要读取网络上的一些图片资源。话说以前倒是用过Python 的requests 对指定网址进行过POST和GET操作,想必读取图片应该用GET操作就可以了吧。
为了进行测试,我首先选择了一个图,虽然只是读一个图片,但是我们的征途是星辰大海。:
这图的地址是:
https://cdn.pixabay.com/photo/2018/08/14/13/23/ocean-3605547_960_720.jpg
然而我尝试直接保存,却保存成为了ocean-3605547_960_720.webp,第一次见到这个webp格式,查了一下:
WebP是Google新推出的影像技术,它可让网页图档有效进行压缩,同时又不影响图片格式兼容与实际清晰度,进而让整体网页下载速度加快。
直接保存
不管了,我就按JPEG格式来保存试试吧,于是写了如下代码:
1 | url = "https://cdn.pixabay.com/photo/2018/08/14/13/23/ocean-3605547_960_720.jpg" |
运行后,显示出的r.content的长度为:81621,看一下生成的图像:
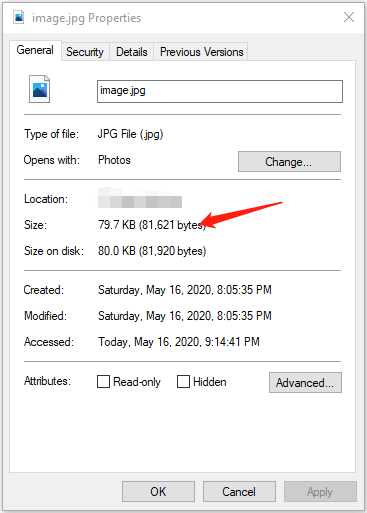
打开后也正常显示,说明这样读取/保存还是没有没问题的。
流形式保存
尽管上述方法可以直接保存图像,不过我查网上好多资料都是建议用iter_content()方法循环获取文件流信息。
直接上代码,需要注意的是requests.get中设置stream=True
1 | url = "https://cdn.pixabay.com/photo/2018/08/14/13/23/ocean-3605547_960_720.jpg" |
这样做的好处,我猜测有两点:一是节省内存开销;二可以获取进度(通过r.headers['content-length']获取总长度信息)
使用第二种方法获取的图像与第一种方法获取的并没有什么区别,所以就不贴截图了。
使用r.raw
另外一种方法就是使用r.raw,因为我并不打算用这种方法,所以只是简单测试一下。
需要注意的是:
- 使用
r.raw,必须设置stream=True - 使用
r.raw之前不能使用r.content之类的调用,否则相当于把输出读光了。 - 使用
r.raw.read(10)读取数据后,数据剩余长度会相应的减少r.headers['content-length']。
requests文档中还有这样一段:
An important note about using Response.iter_content versus Response.raw. Response.iter_content will automatically decode the gzip and deflate transfer-encodings. Response.raw is a raw stream of bytes – it does not transform the response content. If you really need access to the bytes as they were returned, use Response.raw.
也就是说Response.iter_content会自动解码gzip压缩等,而Response.raw就是原始的字节流。所以还是老实地用Response.iter_content 或者直接用Response.content吧。😀
总结
尽管读图片有很多方法,但是因为我要读取的都是一些小图片,不会有多大内存开销,所以第一种方法足够了。
一个需要注意的地方就是在处理之前,先判断一下HTTP 状态码(r.status_code),正常返回应该都是2XX。
够用就好,否则又变成孔乙己研究茴香豆几种写法的问题了,白白地浪费时间和精力。
相关链接
- webp格式
- https://requests.readthedocs.io/en/master/user/quickstart
- How to download image using requests
This page is synchronized from the post: ‘每天进步一点点:requests 读取网络图片’