昨天学习了一下如何在Linux(Ubuntu )下装R(还好我们学的是R语言,而不是B语言😰),并且简单测试了一下如何使用。详情可以参考《学R:准备工作》,今天来继续学R。

(图片从 @dapeng 的帖子里偷的)
运行脚本
昨天我摸索出来执行R脚本的命令为:
R --slave -f hello.R
今天发现原来有一个专门的指令做这个工作:
Rscript
比如对于上述命令,我们可以修改为:
Rscript hello.R
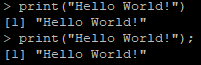
除此之外,我们还可以用-e来直接执行一些语句,比如:
Rscript -e "1+1"Rscript -e 'print("Hello World");'Rscript -e "print(\"Hello World\");"Rscript -e "print(\"Hello World\");1+1;2+2"
安装软件包
在使用Python语言时,我们知道可以使用pip指令来安装所需的软件包,那么R语言环境下,我们如何安装呢?答案是在R环境的提示符下直接使用类似如下指令即可:
install.packages("example_package")
比如我想安装一个caTools的东西(我也不知道是啥),这样做就可以鸟:
install.packages("caTools")
注:我是在普通用户账户下执行的R,所以执行上述指令是会提示我:
Would you like to use a personal library instead? (y/n) y
也就是说数据包被安装的本地,如果想安装到全局,估摸应该用sudo R来启动R环境(我瞎猜的,本地安装挺好,就不去测试了)
加载安装好的软件包,使用类似如下指令即可:
library(caTools)
见识一下
尽管”Hello World!”已经超级强大了,但是还是想见识一下更加强大的功能,在R语言的维基百科页面有一个曼德勃罗集合(Mandelbrot set)的例子,略作修改拿来运行一下,长长见识。
1 | #install.packages("caTools") # install external package |

虽然不知道是什么鬼,但是很漂亮,不是吗?
相关链接
This page is synchronized from the post: 继续学R:安装软件包