昨晚微信群里的朋友发来 Utopian.io 提示大家移除对utopian.app以及其它app授权并建议修改密码的通知。然后知道了不少添加了utopian.app授权的用户账户被用来差评 haejin 的帖子以及随机(?)点赞一些帖子。

(图源 :pixabay)
Utopian.io 被黑
今早 @utopian-io 发了个帖子 Utopian.io Hack - May 3rd - May 4th 2018. No Wallets Or Keys Compromised.说明了这个事件。大致是Utopian.io系统漏洞被发现,然后先是导致Utopian.io服务终止,然后黑客删掉了Utopian.io主服务器的数据,删掉了Utopian.io CDN的数据。
服务中止和数据被删其实对用户影响并不大,但是接下来的事情就严重了,Utopian.io数据库中保存的SteemConnect Tokens被黑客拿到,黑客利用Tokens差评haejin的帖子以及点赞一些其它的帖子。所以如果你是 Utopian.io 用户,在 https://steemd.com/@yourid 上浏览你近期操作,你可能会发现类似如下记录:

Utopian.io 的用户有不少是steem上的知名用户,还好这个黑客不太过分,如果他再利用用户账户发一些钓鱼的帖子或者回复,那么后果将难以想象。
授权机制
@utopian-io的 帖子中说到,用户钱包以及私钥不会受此次被黑事件的影响。这是因为无论是Utopian.io还是SteemConnect 都不存储用户私钥的,而是通过steem的授权体系实现用户对app的授权。
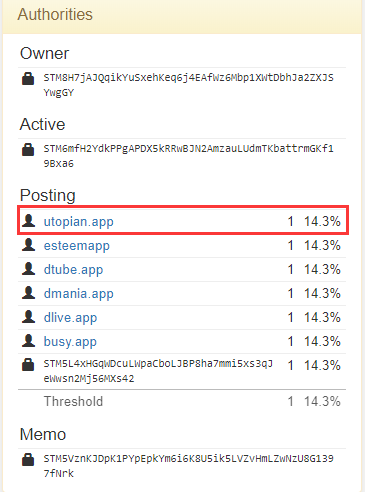
以上边这个我随便找出的用户为例,用户在Posting处添加了utopian.app以及其它app的授权,这些app就可以用自己的私钥以用户的名义去做Posting相关的事情(发帖、回复、点赞、差评等等)
实际上这些app再次授权给 @steemconnect,最终操作的执行者为 @steemconnect 。昨天事件发生时,我写了个脚本,通过transaction的签名数据来判断对应操作的实际操作者。比如这个差评操作: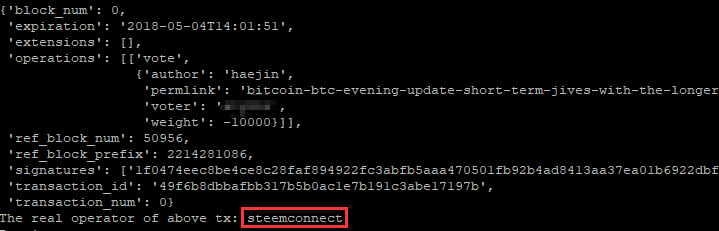
其它问题
@utopian-io 的 帖子中提到:

这个应该取决于你选取的授权范围(我不确定这些app站点是否提供转账等授权)
@utopian-io的 帖子中提到:

“you are totally safe to use SteemConnect in the future.” 我觉得这么说是相当不负责任的,没有那个站点可以保证永远不被黑,只能说看黑客的手段是否高明,况且即便没有黑客,内部出问题呢?所以正确的说法应该是: SteemConnect 以及其它app 暂时不受此次事件的影响。
其它的关于所有相关tokens都已经移除,用户不用改密码这些应该是这样的。至少按此次事件情况以及当前披露的信息,对用户的影响(可能用来发帖、点赞、差评等)已经不存在了。
其它的,比如撤除对某人的差评等,大家就自己看着办吧。
移除授权
另外关于如何移除对第三方app的授权,会操作steempy的,可以使用steempy disallow命令来实现。不会操作steempy的可以使用如下链接操作:
https://v2.steemconnect.com/revoke/@utopian.app
如果需要移除其它账户,将@utopian.app 换成对应账户即可。
另外,从这次事件来看,steemconnect 的拥有所有第三方app(通过steemconnect授权)的用户的对应权限,这有点让人😵。这贴就不继续讨论了。
相关链接
This page is synchronized from the post: ⚠️ Utopian.io 被黑,你可能关心的一些问题 / 如何移除授权