在给微信公众号增加比特股内盘账户资产查询时,我遇到一个麻烦,bitshares系统中活跃的资产多达740项,不活跃的资产更是数不胜数。而读取账户资产的API返回的账户资产项目中,资产用ID的形式表示。那么,要把资产已可阅读的方式展现,则需要再用ID去查询资产的信息。
另外,资产项目中,资产以整数形式呈现,比如你账户中8.88bitCNY,那么资产项目中保存的数据为88800,所以我们需要知道资产的精度,以便于程序做出正确的处理。
如果是其它程序类型,我们在读回账户资产后,可以再逐项调用API读取对应资产数据(符号,精度等),然后再去进行处理。但是多次调用API会消耗很多时间,而微信又有5秒钟的时间限制。在API节点延迟大、微信时间限制短的前提下,如果一个用户资产项目过多,那么读取用户资产将会遇到问题。

(图源 :pixabay)
原始的解决办法
为了解决这个问题,我在程序中做了一些变通:
- 只处理指定类型的资产
- 将对应资产数据(ID、符号、精度)直接编码在程序中
比如我只支持这些资产:"1.3.0", "1.3.113", "1.3.121", "1.3.1999", "1.3.973"
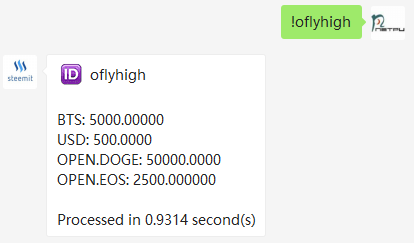
那么获取用户资产的API就可以 这样调用curl -s --data '{"jsonrpc": "2.0", "method": "get_named_account_balances", "params": ["oflyhigh", ["1.3.0", "1.3.113", "1.3.121", "1.3.1999", "1.3.973"]], "id": 1}' https://openledger.hk/ws
返回内容如下: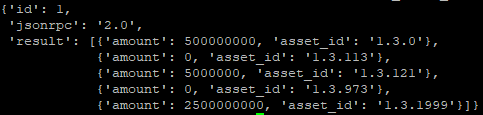
然后在程序中,我就可以这样逐项处理返回的资产:
1 | switch($asset["asset_id"]) |
然后再去处理资产余额以及符号等就方便了。
新的办法
上述方法,在处理几项有限的资产时,没有什么问题。但当资产数目达到十多项时,我发现我彻底懵逼了。这些ID都是啥啊,和谁对应啊?我陷入彻底的混乱当中。于是我在想,必须对这部分代码进行重构了。
首先,我制作了这样一个包含数组的数组:
1 | $assets = array( |
上述数组中保存了,我程序支持的一些资产的数据(ID、符号、精度)
但是该如何使用这个数组我遇到一些问题。
生成资产ID列表
前边我们说过,我使用get_named_account_balances这个API调用返回账户资产,除了传入账户名以外,还要传入要获取的资产列表,比如:"1.3.0", "1.3.113", "1.3.121", "1.3.1999", "1.3.973"
那么如何从上述数组中生成列表呢?
一种方式是我做一个循环来遍历数组元素,获取每项资产的ID,生成新的数组。一听起来就不优雅。于是我使用了如下代码生成列表:
1 | function get_id($v){ |
其中使用了PHP函数array_map以及我们自己定义的回调函数,是不是看起来就很先进?
查询数组
继续回到我们的问题上来,在前边我们说过,之前我们使用switch分支处理,来处理每项资产。那么有了上述资产数组定义后,我们当然不能在继续用分支处理了。那么如何处理呢?
一种方式还是循环,循环是万能的,循环然后对比资产ID,对上了,再去处理。这样做的一个弊端是需要循环好多次,效率低下。
另外有一些类似使用回调函数搜索数组的功能,看了一下感觉效率也不会高到哪里去。
从我们阅读的角度来看,我们知道了某个ID,可以直接去数组中找到对应项,那么我们程序中该如何实现呢?想了一下,最好的办法是给数组定义的时候用ID做KEY,
1 | $assets = array( |
啊啊啊啊,这写法触发了我的强迫症,太不优雅了!让我这样写代码不如杀了我吧,那有没有办法让程序自动给它加上KEY呢,这样就眼不见心不烦了。
最终,我终于找到一种方法
1 | function get_id($v){ |
其中使用了PHP函数array_combine将KEY和原来的数组组合起来。其中前些行代码我们之前就用到了, 所以只多了最后一行代码哦。
修改数组
在读回用户账户资产后,我们需要对用户的每项资产进行处理,计算数值、加上名称等等
比如将{'amount': 500000000, 'asset_id': '1.3.0'}处理成类似5000 BTS的样子
于是我写了类似如下的循环
1 | foreach ($balances as $asset){ |
然而执行完毕,居然啥都没有变,还好脑袋里还有按值传递按引用传递的概念,将代码修改如下:
1 | foreach ($balances as &$asset){ |
瞬间搞定。
新增资产
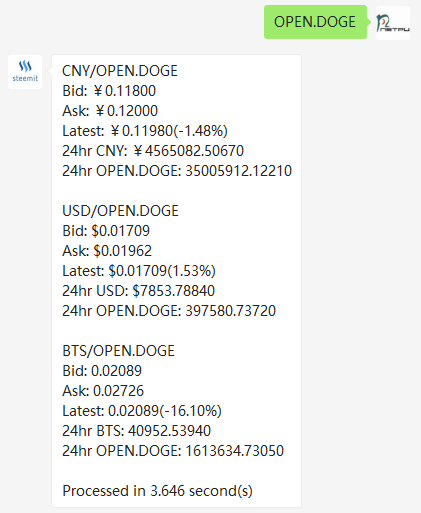
有了上述工作后,再新增加新的资产变得特别方便。比如我们要加入OPEN.DOGE支持,只需在上述数组中加入新的条目:array("symbol"=>"OPEN.DOGE", "id"=>"1.3.860", "precision"=>4),
增减资产从此变得如此简单。
总结

(图源 :pixabay)
通过简化处理资产的类型以及在程序中直接编码资产的数据,使得微信公众号可以很迅速得响应查询账户资产的请求。
通过使用array_map、array_combine、按引用传递以及嵌套函数定义等,使得程序更加便于阅读和维护。
PHP果然是世界上最好的语言,哈哈哈,不服来辩!
相关链接
- http://php.net/manual/en/function.array-map.php
- http://www.php.net/manual/en/function.array-combine.php
This page is synchronized from the post: PHP是世界上最好的语言 / 重构了部分代码