我们知道STEEM体系中,在处理STEEM和SBD之间转换时,使用的价格是median_history_price or feed price
比如说以下场景:
- 在钱包中将SBD转化成STEEM
- 系统发放文章奖励
- 钱包中显示账户估值
使用这个价格的原因在于,这个价格相对而言比较稳定,不会大起大落,比较适合用于处理以上任务。

(图源:pixabay)
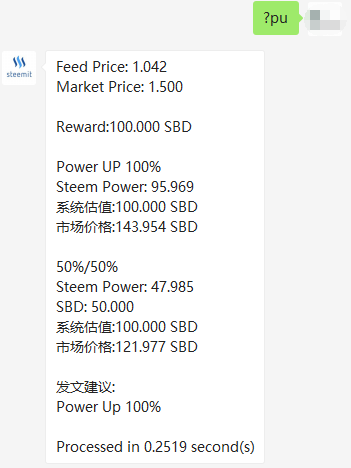
但是,有时候,median_history_price 与内部市场的价格偏差比较大,比如我写作本文时
Feed price
Bid orders & Ask orders

不难看出,这两个价格偏差极大。
于是我们就有了, 发文时选择Power UP 100% 是否合算的问题?
为了方便自己和他人,我特意给微信公众号加了一个辅助大家判断的小功能。
老生常谈,是否100% Power UP? 公众号新功能!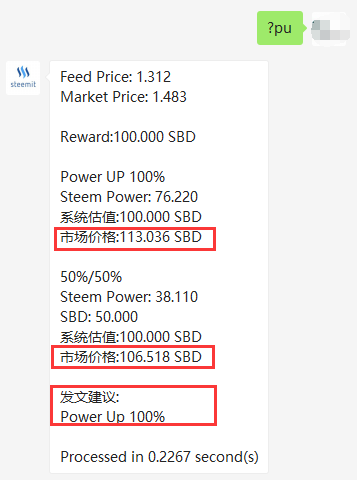
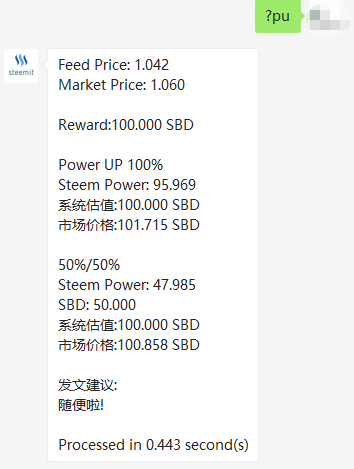
以100SBD的作者奖励来比较,在当前价格下:
- Power UP 100% 获得的奖励,市场价值约:113.036 SBD
- 50%/50% 情况下获得的奖励, 市场价值约:106.518 SBD
我们据此给出判断:发文建议: Power Up 100%
问题所在
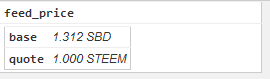
一切似乎都很正常,直到有一次我测试时发现,偶尔出现了 Market Price: 1.000 或者 Market Price: 2.000这样的数据。
在这两天市场价格一直在1.2 - 1.6之前徘徊的情况下,无论是1.000的极低价格还是2.000的极高价格都是不合理的。莫非是我抓的数据有错?看了一下内部市场的成交历史,竟然发现类似这样的数据: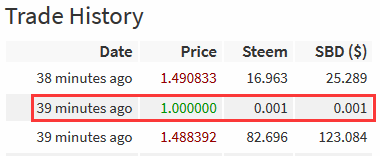
我不清楚内部市场交易撮合的规则,但是既然这样的交易数据实实在在的存在,那么由此可见并非是我的错。
但是,无论是谁的错,这样毛刺数据,都是不可接受的,一旦出现这样的毛刺数据,我的辅助判断就可能出现极大的错误!
如何解决
找出问题,不是我们的目的。找出并解决问题,才是我们要做的。
既然毛刺数据会影响我们的判断,那么我们就要想办法消除毛刺,用我做平衡车姿态分析啥的时候常用的术语叫做滤波。
我们之前采取的方法是,get_ticker,从中我们可以获得:
最高买单价格,最低卖单价格,以及最后一笔成交价格等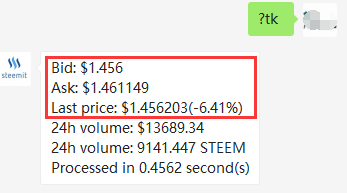
我们之前辅助判断功能中采取的就是Last price,因为最后一笔交易可能是成交量极小的毛刺交易,所以偶尔会导致这个价格极度失真。
那么都有哪些方式可以解决这个问题呢? 我大致想到如下方法:
- (Highest bid+Lowest ask)/2 的方式
- 多获取一些Trade History,并用成交数据中的SBD/STEEM来判断价格
- 获取N档order book,用其中的价格或数量来计算参考价格
对于第一种方式,由于steem内部市场不是很活跃,有时候还好,但有时候Highest bid以及Lowest ask差额巨大,单单取中间值,不是很合理。
对于第二种方式,同样steem内部市场不是很活跃,可能之前一笔成交订单已经过去了好长时间,这样取N比订单,计算参考价格,可能数据会比较陈旧。
第三种方式,相对比较合理,通过当前的买单和卖单来计算出参考价格,无疑是相对比较合理的。
以获取五档order book为例,我们会得到类似如下数据: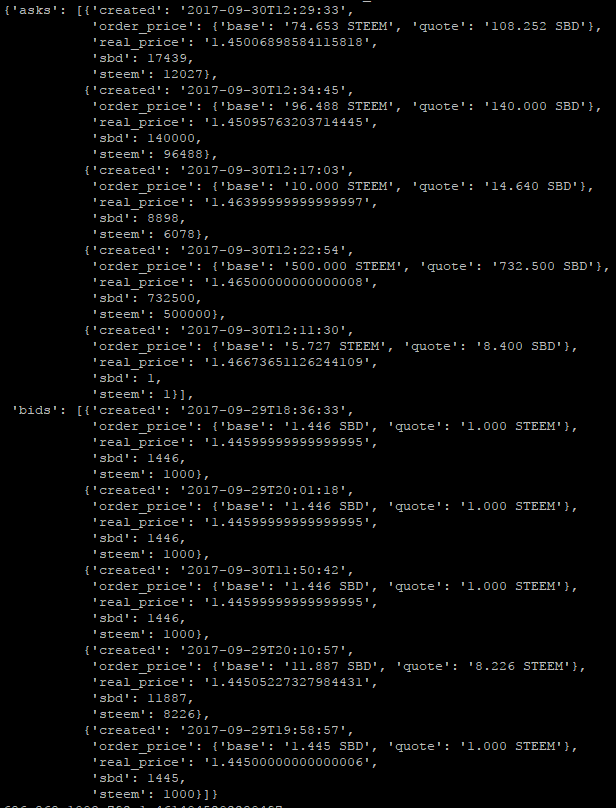
我们有几种选择
- 将所有price数据平均
- 对买单的’base’与’quote’求和并计算出买单价格,同理计算出卖单价格,取平均值
- 对所有买单以及卖单的’base’与’quote’求和,直接计算出价格
- 对所有卖单以及卖单的sbd以及 steem求和,计算出价格
通过测试,发现在不同场景下,以上几种方案计算出去的数据,差额极大。
以上述数据为例,后三种方案算出的价格分别为:
- 1.4533425349381701
- 1.4611225385999593
- 1.4621550046265275
可见,计算出来的价格更倾向于反应买卖双方的期望价格。当市场价格趋于平稳时,这个三个计算出来的价格均在Highest bid与Lowest ask之间,差异不大。当市场暴涨或者暴跌时,这个三个计算出来的价格会有严重的倾向性,甚至会超出Highest bid与Lowest ask的范围。超出Highest bid与Lowest ask的范围是否代表不合理,也不尽然。但是上述计算出的数据显然不合理。或许我们根据卖单与买单的量,以及历史成交价格,据此判断出上涨或者下跌的趋势,进而对上述结果进行修正,才会得出趋于合理的数据吧。
再回头看,我们不过要一个市场价格的参考价格,用于判断是否适合Power UP 100%, 有必要搞这么复杂吗?心累!
那就随便用一种方式好了,毕竟都差不多嘛。以后请叫我差不多先生。😭
This page is synchronized from the post: 如何计算内部市场当前参考价格