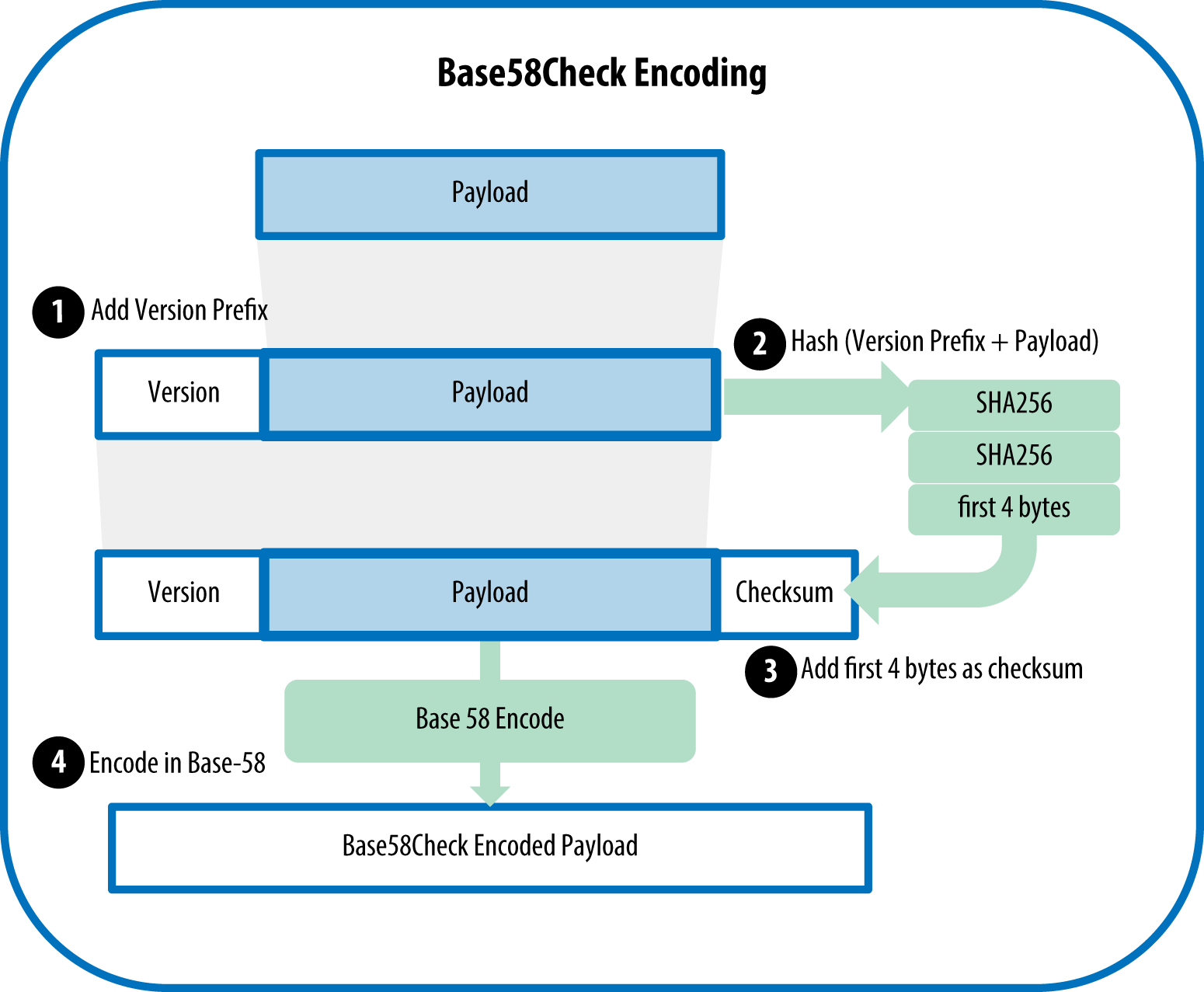
To add extra security against typos or transcription errors, Base58Check is a Base58 encoding format, frequently used in bitcoin, which has a built-in error-checking code. The checksum is an additional four bytes added to the end of the data that is being encoded. The checksum is derived from the hash of the encoded data and can therefore be used to detect and prevent transcription and typing errors.
Base58Check的特色
以下是上述Wiki中介绍的Base58Check的特色
An arbitrarily sized payload.
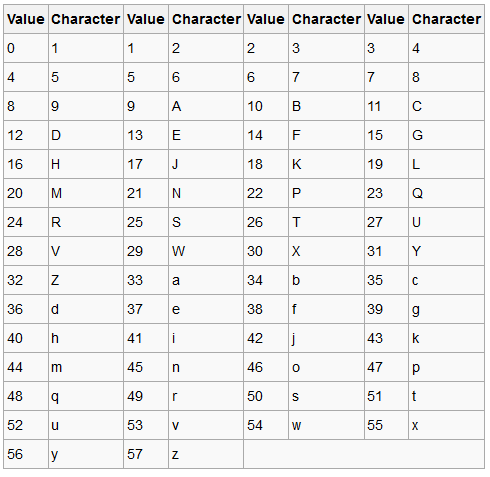
A set of 58 alphanumeric symbols consisting of easily distinguished uppercase and lowercase letters (0OIl are not used)
One byte of version/application information. Bitcoin addresses use 0x00 for this byte (future ones may use 0x05).
Four bytes (32 bits) of SHA256-based error checking code. This code can be used to automatically detect and possibly correct typographical errors.
An extra step for preservation of leading zeroes in the data.
上述步骤在《Mastering Bitcoin》一书中有一个图,很好的说明了这个过程 (Figure 4-6. Base58Check encoding: a Base58, versioned, and checksummed format for unambiguously encoding bitcoin data) Image source Here
Compared to Base64, the following similar-looking letters are omitted: 0 (zero), O (capital o), I (capital i) and l (lower case L) as well as the non-alphanumeric characters + (plus) and / (slash)
输入文本串的时候傻傻的分不清出0和O, I 和l 有木有?中枪的🙋 这个Base58就避免了这个问题,看来凡事出现都是有缘由的。
听说还有个变种Base56,去的更彻底,不过咱没遇到,就不研究它了
A variant, Base56, excludes 1 (one) and o (lowercase o) compared to Base 58.
def base58decode(base58_str): base58_text = bytes(base58_str, "ascii") n = 0 leading_zeroes_count = 0 for b in base58_text: n = n * 58 + BASE58_ALPHABET.find(b) if n == 0: leading_zeroes_count += 1 res = bytearray() while n >= 256: div, mod = divmod(n, 256) res.insert(0, mod) n = div else: res.insert(0, n) return hexlify(bytearray(1) * leading_zeroes_count + res).decode('ascii')
def base58encode(hexstring): byteseq = bytes(unhexlify(bytes(hexstring, 'ascii'))) n = 0 leading_zeroes_count = 0 for c in byteseq: n = n * 256 + c if n == 0: leading_zeroes_count += 1 res = bytearray() while n >= 58: div, mod = divmod(n, 58) res.insert(0, BASE58_ALPHABET[mod]) n = div else: res.insert(0, BASE58_ALPHABET[n]) return (BASE58_ALPHABET[0:1] * leading_zeroes_count + res).decode('ascii')
/** This is a rough approximation of log10 that works with huge digit-strings. Warning: Math.log10(0) === NaN The 0.00000001 offset fixes cases of Math.log(1000)/Math.LN10 = 2.99999999~ */ function log10(str) { const leadingDigits = parseInt(str.substring(0, 4)); const log = Math.log(leadingDigits) / Math.LN10 + 0.00000001 const n = str.length - 1; return n + (log - parseInt(log)); }
let out = log10(rep) if(isNaN(out)) out = 0 out = Math.max(out - 9, 0); // @ -9, $0.50 earned is approx magnitude 1 out = (neg ? -1 : 1) * out out = (out * 9) + 25 // 9 points per magnitude. center at 25 // base-line 0 to darken and < 0 to auto hide (grep rephide) out = parseInt(out) return out }