QQ 号被腾讯打劫走
前些天,我珍藏十数年的几个7位8位QQ号,被腾讯统统冻结了。
说神马发送非法信息,丫的找个借口都不优雅,你就直接说抢劫,简单粗暴,多好。
我合计冻结总归可以解冻吧,然而答案是: NO
又要填写历史密码,又要好友验证的
问题是我历史密码就一个呀,至于好友,我这些QQ里边还没有好友呢。
总之,就是我这组价值连城的7位8位号,就这么被腾讯抢走了
估计过一段时间,就会被包装成靓号出售吧
总之,在腾讯这样的强权帝国里,你的东西属不属于你,腾讯说了算!
基于区块链的聊天工具
对腾讯的行为我虽愤慨,但是无能为力!
然后我就想,有没有一种聊天工具,属于你的就是属于你的,谁也抢不走呢?除非你主动把它送给别人。
但是,但凡是中心化的聊天工具,总有这样的弊端,毕竟人家的地盘,你做不了主。
那么是不是也可以考虑去中心化呢?把聊天工具挪到区块链上来,似乎是个不错的想法呢 😀
可是神马乱七八糟的区块链的东西我都不熟悉啊,就知道STEEM和比特币、BTS、ETH、EOS
除了STEEM,后边几个也基本上处于仅仅知道的尴尬境地
那有没有可能弄一个基于STEEM区块链的聊天工具呢?
基于STEEM区块链的聊天工具
好,咱继续YY发挥想象力。
1) 利用发帖
说到STEEM,我们常做的行为就是发帖、回帖、点赞、转账等等
如果用发帖功能做聊天工具,呃,让我想想一下,打开STEEMIT首页,满屏幕都是
“你好”
“你好”
“你今天吃饭了吗?”
“吃了”
“你呢?”
“我也吃了”
…….
一句话一个帖子,画面太美,我不敢继续想象了
2) 利用回帖
既然利用发帖做聊天工具实施起来有些那啥(那啥是啥?),那么利用回帖呢?
然后,假设聊点敏感话题
今天我们去哪开房?
阳光宾馆215室?
完蛋了,大家都能看到,曝光了吧!
还有,回帖限制是20秒一个,这聊的也不痛快啊。
3) 利用转账
既然用发帖、回帖做聊天工具都不现实,那么还有啥办法?用点赞?用差评?别逗了,点赞咋传递文本信息啊?莫非把点赞百分比编码,比如1%代表A,2%代表B,那发送个”I love you”得点多少下啊,况且也没那么多帖子点啊。
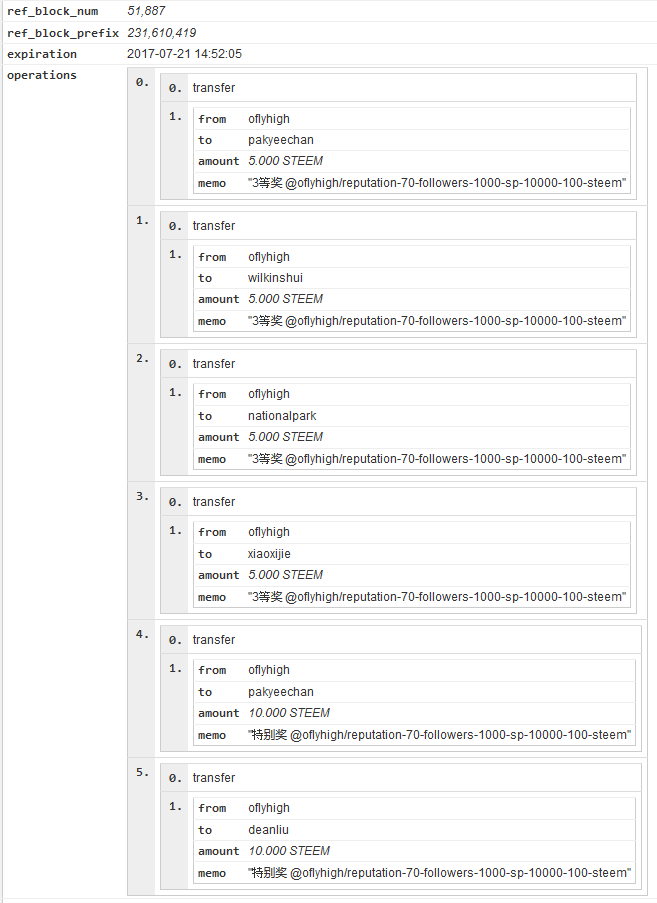
想来想去,最靠谱的就是转账功能呢
重要的是,转账功能自带MEMO,我们可以在MEMO里传递信息啊
更重要的是,转账MEMO带加密功能,去宾馆开房再也不怕别人看到啦
基于STEEM 转账功能的聊天工具
好了,我们越来越能YY了,我们的思路越来越清晰了。
既然明确了可以用转帐功能实现聊天工具,那具体咋做呢?如果说登陆steemit 转账,那还用你说嘛?所以我们必须进一步YY
我们必须要有桌面端和移动端APP,网页版的也要开发,这样才显得高端大气上档次,低调奢华有内涵!
程序监控指定格式转账信息
要接到别人发来的聊天信息,我们必须监控到我们账户的转账信息。
当然为了和其它转账信息区别开来,我们可以加上特定的格式,举例说,以chat:开头
我们在程序中监控转账信息,并取得memo,当然了,如果是加密的就先解密好了
发现以chat:开头,哇, 有人找我聊天了耶,是要请我吃饭还是要开房?快显示出来看看
然后程序在窗口里显示出来聊天内容,哇,原来是讨债的,假装没看到好了
程序支持发起转账
既然是聊天工具,当然要能收能发,通过监控功能,我们已经能实现接收信息
那么收到了信息必须要回复啊(讨债的除外),否则多么不礼貌。
所以程序也要支持给别人转账
在输入框中 @你要传送消息的人,并附上文本内容即可
程序自动发起一条转账信息,并将文本内容替换成 chat: 文本内容附加在memo里
当然,你也可以设置成自动加密
程序支持高级功能
好了,YY到这里,分析到这里,我们已经有了个基于STEEM区块链的聊天工具。
但是这貌似功能挺低端啊
别急这只是基本功能嘛,在这个基础上,我们可以做好些事情呢?
我要开始放大招了,真的是放大招了,不骗你,大招来了
最最高级的功能,是我们可以通过设置金额门槛来实施消息过滤
啥意思?就是说,我设置5STEEM门槛,你转账1STEEM过来的聊天信息我统统忽略。
有啥意义?这你还不懂嘛?防骚扰利器啊!!!
想和我聊天,嗯哼,拿钱来!
5毛钱你是埋汰我,10块钱聊两条,陪聊明码实价喽
突然觉得我好庸俗……
好了,不谈钱,伤感情!
人家QQ啥的那么多表情啥的,你这个聊天工具干巴巴的,多没意思!
表情其实是很简单的啊,实现起来So easy啊,只要加个表情库,然后给个编码,比如大圆笑脸就是 /:ka,这不是很简单的事情嘛,各种表情包也是一个道理。
至于发照片,传文件也都可以,发个URL嘛,实际内容可以偷摸上传到steemit的图片服务器上去。
语音,视频这些都可以有
只是咋实现我就不懂啦。
面临的问题
唯一可能是障碍的就是现在STEEM是3秒中一个块
这样文本聊天达不到实时的要求,不过貌似不算啥大问题了
多给你一点时间思考,以免发出去不经过大脑过滤的内容
另外EOS上这个时间是不是变短了呢?
咱们这个聊天工具可以直接迁移到EOS上嘛
结论
- 通过STEEM转账功能实现聊天工具(IM)应该是可行的
- 可以利用MEMO加密功能来实现消息加密
- 可以通过转账金额限制来实现防骚扰等高级功能
- 可以方便的移植到BTS或者EOS上
哇,太完美了,你们谁去写个白皮书,ICO吧
记得若是发家了,分我一些啊
后记
写完之后,搜索了一下,居然发现一个叫ECHO的东西
简单了解一下,就是石墨烯加上IPFS,额,比我这个多了个IPFS
但是咱也不是没有优点啊,咱们的优点就是无需额外的弄什么ECHO了
有STEEM账户,有BTS账户,有EOS账户,就可以用我们的聊天工具
至于IPFS,加上呗(话说咋加?)
好了,大家都来用我们的聊天工具吧,炒鸡简单,炒鸡好用,炒鸡安全
你问我去那下载?
呃。好吧,我YY过头了……
This page is synchronized from the post: YY 一个基于STEEM区块链的聊天工具