在昨天的帖子中,我提到通过改写bitCNY抵押率排行榜的实现代码来加快程序的处理速度。为了衡量程序改进前后的差异,我在代码中计算了一下程序执行时间,通过对比时间来判断效率提升了多少。

封面图源:https://pixabay.com
其实,计算代码执行时间是很简单也很常用的功能,但是对于我这个半路出身的程序员,尤其还是个记忆力不佳的程序员,每次都要查查文档或者参考一下以前自己写过的代码才能写出来。这种感觉很不好,于是我决定把这个整理一下记下来,这样下次我再用的时候,搜索一下steemit即可✌。
程序执行时间分为两种情况,一种是CPU时间,一种是运行时间。
CPU时间
CPU时间即程序占用CPU的时间,对于非程序员可能有点费解,时间就是时间还有啥运行时间和CPU时间呢?我举个简单的例子就懂了,比如我们每天上班要和电脑打交道,但是除了和电脑打交道的时间,我们还要在上下班路上浪费时间、中午去食堂吃饭浪费时间、接杯咖啡喝瓶可乐什么的要浪费时间、和美女同事聊天浪费时间、偶尔去趟厕所也要浪费时间、还有可能坐在座位上发呆也在浪费时间…… 也就是说,尽管你每天上班8个小时,但可能在电脑上工作的时间不超过一个小时。
对于程序而言也是一样,我们写一个程序开始执行,程序中可能有延时等待、可能有磁盘和网络IO操作、可能要等别的进程释放CPU占用等等,简而言之,它不是一直占用CPU的,而它实际占用CPU的时间就称之为CPU时间。
扯远了,在Linux系统下,Python程序中可以用下列代码计算程序占用的CPU时间:
但是呢,据说这个time.clock有点不好用(其实我觉得挺好啦),主要有两点:
- Linux下和Windows下行为不一致。
Linux不包含程序睡觉的时间,Windows下包含了睡觉时间; - 这个函数在Windows下精度更高,在Linux下精度不高。
所以在Python 3.3以后引进了两个新的东东
time.perf_counter(), benchmarking, most precise clock for short periodtime.process_time(), profiling, CPU time of the process
感兴趣的自己看文末参考资料吧,我头有点大。
程序运行时间
在昨天的帖子中,我提到老版本的生成bitCNY抵押率排行榜程序生成100条记录需要105,而新版本的只需要3秒,这个时间就是我们从计时开始到计时结束所耗费的时间。
其中 time.time()获取当前时间戳,在Linux以及大多数系统下,时间戳是距离January 1, 1970, 00:00:00 (UTC)的秒数,其实我们取得是差额,基准是谁都无所谓啦。
测试
将上述代码应用到我们老版本的bitCNY抵押率排行榜程序中
输出结果如下: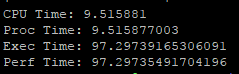
同样的代码,代入我们新版本的程序中,输出结果如下: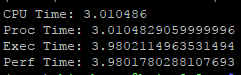
由此可见我们的新代码无论从CPU占用还是执行时间上来讲,都得到了大幅改善。
参考内容
- https://www.python.org/dev/peps/pep-0418/
- https://docs.python.org/3.6/library/time.html#time.clock
- https://docs.python.org/3.6/library/time.html#time.perf_counter
- https://docs.python.org/3.6/library/time.html#time.process_time
- https://docs.python.org/3.6/library/time.html#time.time
- https://docs.python.org/3.6/library/time.html#epoch
This page is synchronized from the post: Python 计算程序CPU时间以及运行时间