之前写了两篇关于STEEM/HIVE私钥和公钥的文章,大致搞明白了私钥和公钥是怎么弄出来的。接下来新问题来了,在STEEM/HIVE中,私钥和公钥都是编码后可阅读的方式,那么使用时又是如何还原的呢?

(图源 :pixabay)
今天我们就来一起探索一下。
私钥的还原
我们先来看私钥,我们之前得出的结论是:
STEEM/HIVE使用的私钥,就是加了前缀(0x80)和校验码并用Base58Check编码的256位二进制随机数。
我发现之前的说法逻辑有些混乱,其实应该修改为:
STEEM/HIVE使用的私钥,就是加了前缀(0x80)和校验码并用Base58编码的256位二进制随机数。而这个过程称为
Base58Check。
我们再来看Base58Check的编码流程:
( Source: 《Mastering Bitcoin》)
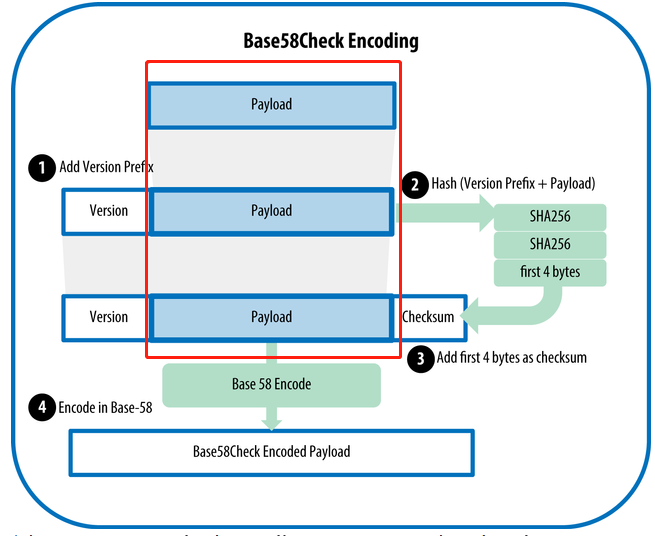
从中不难发现,其实Payload部分(红框标出部分)是没有被编码过程破坏的,那么还原的过程其实就是先用Base58解码,然后去掉version和checksum部分即可。
steem-python中代码如下:
1 | def base58CheckDecode(s): |
其中和checksum相关的两句,用于检测私钥是否合法(校验checksum),对于一个合法的私钥,这两句不影响结果。
公钥的还原
在之前公钥的文章中,我们得出如下结论:
STEEM/HIVE使用的公钥,生成方法和比特币中公钥的生成没有区别,也有压缩和非压缩两种。然后STEEM/HIVE中使用
gphBase58CheckEncode对其中的压缩公钥进行编码,并加上STM前缀。
相比于私钥复杂的Base58CheckEncode,公钥的gphBase58CheckEncode要简单得多:
1 | def gphBase58CheckEncode(s): |
从代码中不难分歧,其实就是使用ripemd160(payload)并截取前四个字节作为校验码,然后和payload一起并用base58编码处理。
所以,逆向的过程也并不复杂,steem-python中对应代码如下:
1 | def gphBase58CheckDecode(s): |
因为并没有两个字节的Version前缀,所以去掉checksum就可以了。同样,代码中和checksum相关的两句,用于检测公钥是否合法(校验checksum)。
对STEEM/HIVE公钥而言,另外一个地方就是公钥前边的STM前缀,这个我们可以将公钥传递给gphBase58CheckDecode之前去掉就可以了。
测试
我们继续用之前的测试代码(生成私钥和公钥),然后在把私钥和公钥还原成原始的16进制字符串形式,并与原始的私钥/公钥对比。
代码执行结果如下:

可见还原回来的私钥和公钥和原始的是一样的。
结论
私钥/公钥从可阅读的编码字符串还原成原始的字符串还是很容易的,私钥就是使用base58CheckDecode解码并去掉前缀和校验码,公钥就是使用gphBase58CheckDecode解码并去掉校验码。
相关链接
This page is synchronized from the post: ‘每天进步一点点:STEEM/HIVE私钥/公钥的还原’