一般情况写一些技术相关的内容时,我都会做足够的测试,来支持我的每一点结论。所以涉及到技术问题时,我一般都附带代码以及执行结果,没有什么比执行结果更有说服力了。
比如今天的《Requests 与 HTTP Keep-Alive》,无论从代码的执行时间还是从调试信息上来看,都证明Requests的会话(Session)中可以自动实现持久链接(Keep-Alive)。

(图源:https://pixabay.com)
有时候明明看着很简单的东西,为了用代码去证明,然后耗费了很长时间,甚至会遇到一些坑,比如之前介绍Click中遇到的docstring 与help冲突的问题。尽管遇到一些坑,尽管去解决这个坑可能花费了好多时间,但是遇坑填坑的过程就是学习的过程,对此我挺欢喜的。
但是有时候也难免会因为太过于自信,不去测试,就下结论,而犯一些错误。今天要说的就是,我冤枉urllib3了。
SO_KEEPALIVE 不等于HTTP Keep-Alive
在之前介绍urllib3时,我已经介绍过了Requests,并且知道了Requests的会话(Session)中可以自动实现持久链接(Keep-Alive)等高级特性。然后我就想,既然Requests一直强调这是高级特性,而Request使用的是urllib3,那么这些高级功能在urllib3上实现起来,总应该略复杂才对。然后我在其它程序中看到如下代码:
就想当然认为urllib3实现HTTP Keep-Alive要加入上述代码,于是直接在文章中加入了这个结论。
但是今天抽时间测试了一下这个功能,发现加不加上述代码,连接都是Keep-Alive的,那么就说明我之前得出的结论完全错误,另外又产生一个疑问加上述代码有什么意义呢?

通过一番调查,并祭出了我的宝典(200页),又找了好多网页,大致明白了SO_KEEPALIVE相当于在TCP层实现了以个心跳机制,具体是啥我也没太看懂啦(没研究懂之前,我不敢妄下结论啦),总之,和我们要实现HTTP Keep-Alive是两码事,可以看作是HTTP Keep-Alive设置的特性之一。
urllib3 HTTP Keep-Alive的实现
那么urllib3的HTTP Keep-Alive又如何实现的呢?答案是自动实现的。(好像是废话?) 因为HTTP 1.1中默认启用Keep-Alive,所以无需指定诸如:headers={‘connection’: ‘Keep-Alive’}的HTTP头。
那么如何不让它 Keep-Alive呢?(咦,好变态的需求),答案有两个:
- 设置Header,比如headers={‘connection’: ‘close’}
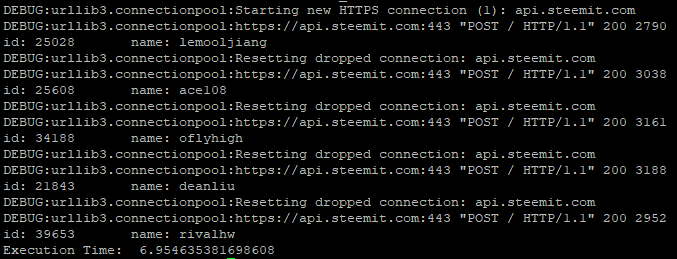
- 每次清理PoolManager
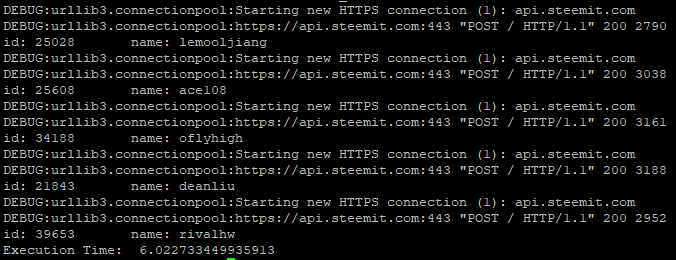
对比一下,Keep-Alive的输出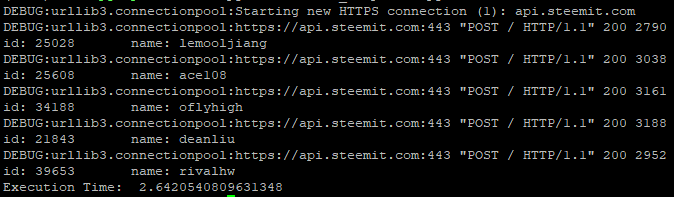
结论
不要在没有做充分调研的时候就妄下结论,否则自己弄错了到无所谓,再误导了别人就不好啦。😳
把这个糗事记录下来,与诸君共勉吧。
This page is synchronized from the post: 冤枉urllib3了,望文生义不可取